If you've been following along the previous posts you should have everything ready to go straight into this one.
Ansible Playbook
After using Terraform to create the infrastructure for the environment, we will use Ansible to actually configure the server. Once again we will be splitting the tasks up into modules, or "roles" as they are called in Ansible land. So first order of the day is to create the structure ready for us to throw stuff into.
mkdir -p ansible/roles/system/tasks
mkdir -p ansible/roles/velociraptor/tasks
touch ansible/dfir.yaml
touch ansible/roles/system/tasks/main.yaml
touch ansible/roles/velociraptor/tasks/main.yaml
mkdir ansible/vars
touch ansible/vars/velociraptor_vars.yaml
The main playbook
Like the top-level terraform main.tf, this file will just call the tasks from the other roles. We instruct it to access the remote host as the velociraptor user. NOTE: You will need to change this if you set your own username, or left it as the default ubuntu. This also applies in various areas throughout this post but I will only point it out here.
- name: Configure Velociraptor server
hosts: {{ domain }}
remote_user: "velociraptor"
vars_files:
- /vars/velociraptor_vars.yaml
- /vars/from_terraform.yaml
roles:
- system
- velociraptor
Remember at the end of our Terraform script we output the dns names for our server and EFS into that from_terraform.yaml file? Yep, Ansible will read from that, reducing the amount of manual input required.
System
This is a small tasklist, it installs a couple of packages that we will need to mount the EFS and set up the server, then mounts the EFS to a directory that will be used by Velociraptor.
- Install some packages, making sure to escalate to root using
become: yes
- name: Install required packages
become: yes
package:
update_cache: yes
name:
- nfs-common
state: latest
- Create a config file directory to hold the Velociraptor configs
- name: Create Velociraptor configs directory
become: yes
file:
path: /etc/velociraptor
state: directory
mode: "0770"
owner: root
group: velociraptor
- Mount the EFS to create the data storage directory.
- name: Mount EFS to create Velociraptor data directory
become: yes
ansible.posix.mount:
path: /opt/velociraptor
src: "{{ efs_dns_name }}:/"
fstype: nfs4
opts: nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport
state: mounted
- Adjust permissions on the storage directory so that the velociraptor user can actually do stuff in it
- name: Give Velociraptor user permissions on mounted data directory
become: yes
file:
recurse: yes
path: /opt/velociraptor
state: directory
mode: "0770"
owner: root
group: velociraptor
Velociraptor
Unfortunately Velociraptor is not installable from a package manager, so we have to download the binaries from the official GitHub repository. Since this is an automation script we don't want the user having to get the links every time so we'll store them in a variables file. It would be wise, however, to update them periodically to ensure you're not stuck using an old version of the tool.
Acquiring the necessary files
- Grab the links to binaries for various architectures from https://github.com/Velocidex/velociraptor/releases and place them in the variables file.
windows_x64: https://github.com/Velocidex/velociraptor/releases/download/v0.6.8-2/velociraptor-v0.6.8-2-windows-amd64.exe
windows_x86: https://github.com/Velocidex/velociraptor/releases/download/v0.6.8-2/velociraptor-v0.6.8-2-windows-386.exe
linux_x64: https://github.com/Velocidex/velociraptor/releases/download/v0.6.8-2/velociraptor-v0.6.8-2-linux-amd64
darwin_amd64: https://github.com/Velocidex/velociraptor/releases/download/v0.6.8-2/velociraptor-v0.6.8-2-darwin-amd64
darwin_arm64: https://github.com/Velocidex/velociraptor/releases/download/v0.6.8-2/velociraptor-v0.6.8-2-darwin-arm64
- Create Ansible instructions to download all the binaries
- name: Create directory to store all Velociraptor binaries
file:
path: /home/velociraptor/clients
state: directory
- Download all the binaries!
- name: Download linux x64 Velociraptor binary
get_url: url="{{ linux_x64 }}" dest=/home/velociraptor/clients/velociraptor-linux-amd64
- name: Download windows x86 Velociraptor binary
get_url: url="{{ windows_x86 }}" dest=/home/velociraptor/clients/velociraptor-windows-x86.exe
- name: Download windows x64 Velociraptor binary
get_url: url="{{ windows_x64 }}" dest=/home/velociraptor/clients/velociraptor-windows-x64.exe
- name: Download darwin amd64 Velociraptor binary
get_url: url="{{ darwin_amd64 }}" dest=/home/velociraptor/clients/velociraptor-darwin-amd64
- name: Download darwin arm64 Velociraptor binary
get_url: url="{{ darwin_arm64 }}" dest=/home/velociraptor/clients/velociraptor-darwin-arm64
- Since we will be using the linux binary as the server we need to make it executable and place a link to it somewhere in our PATH
- name: Set linux Velociraptor binary as executable
command: chmod +x /home/velociraptor/clients/velociraptor-linux-amd64
- name: Create symlink to linux Velociraptor binary
become: yes
command: ln -s /home/velociraptor/clients/velociraptor-linux-amd64 /usr/local/bin/velociraptor
Generating the server and client configs
- Ok, when performing the server configuration we need some specific info that we cannot hard code. So we'll use some interactive prompts to get the info from the user. Go back to the top-level .yaml file and add the following after the
vars-fileslines.
vars_prompt:
- name: username
prompt: Admin username for Velociraptor GUI access?
private: false
- name: password
prompt: Password for the admin user?
- Time to generate our server config. We'll be generating a default config but merging some options into it to override defaults and fit our context.
- name: Generate server configuration file
shell:
cmd: velociraptor config generate --merge='{"Client":{"server_urls":["https://{{ domain }}:9501/"], "use_self_signed_ssl":true},"GUI":{"public_url":"https://{{ domain }}:9500/","bind_address":"0.0.0.0","bind_port":9500,"use_plain_http":false},"Frontend":{"hostname":"{{ domain }}","bind_address":"0.0.0.0","bind_port":9501,"use_plain_http":false},"Datastore":{"location":"/opt/velociraptor","filestore_directory":"/opt/velociraptor"},"Logging":{"output_directory":"/opt/velociraptor/logs"}}' > /etc/velociraptor/server.config.yaml
Yes that is quite ugly without any linebreaks, so if you want a clearer idea of what it is merging I've prettified it below:
{
"Client": {
"server_urls": [
"https://{{ domain }}:9501/"
],
"use_self_signed_ssl": true
},
"GUI": {
"public_url": "https://{{ domain }}:9500/",
"bind_address": "0.0.0.0",
"bind_port": 9500,
"use_plain_http": false
},
"Frontend": {
"hostname": "{{ domain }}",
"bind_address": "0.0.0.0",
"bind_port": 9501,
"use_plain_http": false
},
"Datastore": {
"location": "/opt/velociraptor",
"filestore_directory": "/opt/velociraptor"
},
"Logging": {
"output_directory": "/opt/velociraptor/logs"
}
}
Basically it just changed the bind address from localhost to 0.0.0.0, customises the listening ports and inserts our domain using the variable.
- After that, creating the client config is easy since it is based off of the server one. We'll also add the first user to the server using the variables passed in interactively.
- name: Generate client configuration file
shell:
cmd: velociraptor config client -c /etc/velociraptor/server.config.yaml > /etc/velociraptor/client.config.yaml
- name: Add administrator account
command: velociraptor user add --role=administrator {{ username }} {{ password }} -c /etc/velociraptor/server.config.yaml
Running the server
To actually run the Velociraptor server we need to use the binary and the config file to create an install package, and then install the package to the system.
- name: Create the Velociraptor server installation package
become: yes
command: velociraptor -c /etc/velociraptor/server.config.yaml debian server --output=/root/velociraptor_server.deb
- name: Install the Velociraptor server package
become: yes
command: dpkg -i /root/velociraptor_server.deb
Running the playbook
With the playbook finished it can be run with a simple command. Make sure to supply the correct private key name!
ansible-playbook -i ./ansible/hosts ./ansible/dfir.yaml --private-key ./.ssh/<keyname>.pem
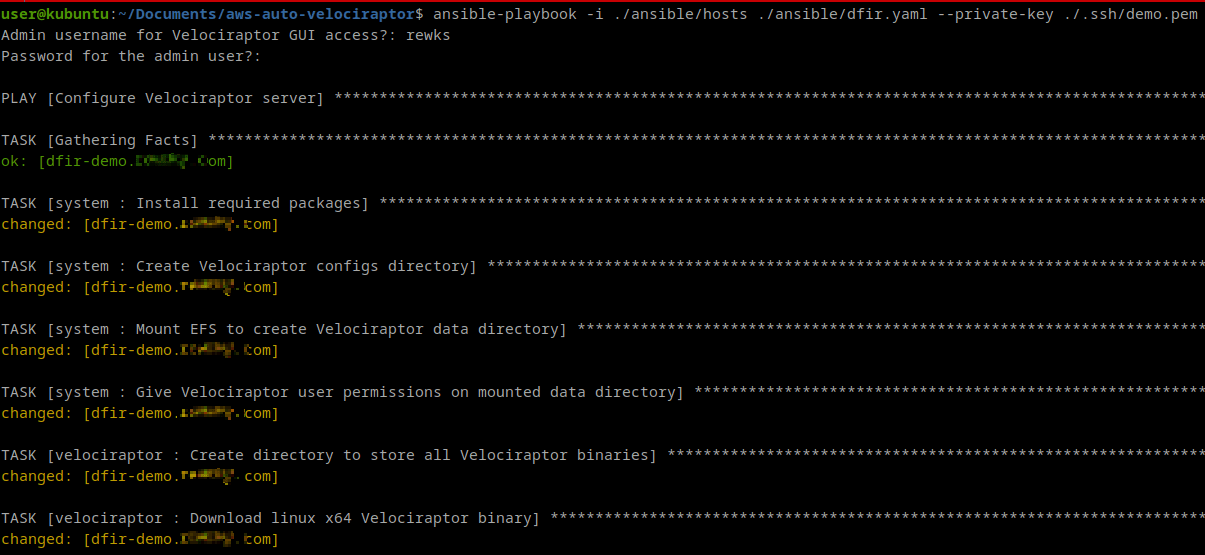
You should get a nice output of all the tasks completing. Once they're all done, open your browser and check out the GUI!
Host keys
One last note - if you're reusing subdomains ansible will kick up a fuss about host keys not matching. Ordinarily a useful warning, in this case we're in control of the infrastructure and domain so it just gets in our way. It can be disabled by creating an ansible.cfg file in the working directoy with the following content
[defaults]
host_key_checking = false
If you've followed along through all three blog posts well done! Hopefully it has been of help to you. Additionally you can find the full code on my github at https://github.com/rewks/aws-auto-velociraptor